http://runmoneyrun.blogspot.kr/2016/03/alphago.html
http://runmoneyrun.blogspot.kr/2016/03/blog-post_12.html
Mastering the game of Go with deep neural networks and tree search
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
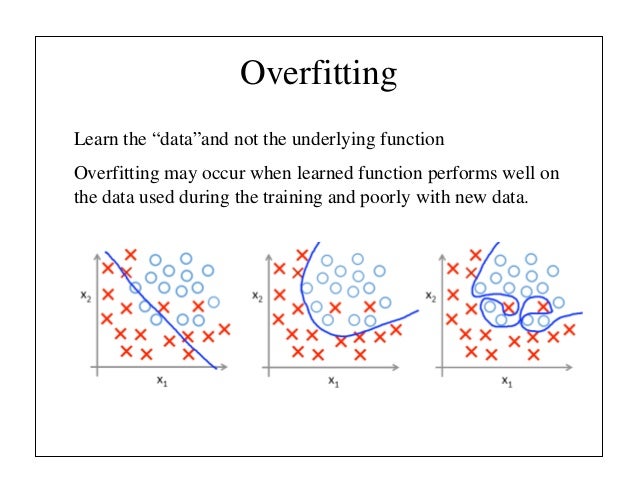
"The naive approach of predicting game outcomes from data consisting of complete games leads to overfitting. The problem is that successive positions are strongly correlated, differing by just one stone, but the regression target is shared for the entire game. When trained on the KGS data set in this way, the value network memorized the game outcomes rather than generalizing to new positions, achieving a minimum MSE of 0.37 on the test set, compared to 0.19 on the training set. To mitigate this problem, we generated a new self-play data set consisting of 30 million distinct positions, each sampled from a separate game. Each game was played between the RL policy network and itself until the game terminated. Training on this data set led to MSEs of 0.226 and 0.234 on the training and test set respectively, indicating minimal overfitting."
네이처 논문을 찾아보니 힌트가 될만한 내용이 있다.
제한된 데이타 셋에 대한 오버피팅을 막기위해 셀프경기를 하면서 3000만개의 서로 독립된 데이타를 쌓았음에도 불구하고 드물게 발생하는 상황에서는 오버피팅을 피할 수 없었다는 것.
4국에서 벌어진 오류(?)가 오버피팅(혹은 다이버전스)의 결과였다면 그렇다는 것이다.
보기에는 딱 그런 느낌이었지만 알 수는 없다.
이세돌은 4국만에 알파고의 약점을 찾아내 승리했고, 인간의 위대함을 보였다.
대신 구글은 원하는 정보를 얻었다.
안정적인 값을 내놓도록 알파고를 세팅해도 바둑의 신같은 실력을 보일 수 있었을까?
궁금하다.
-----------------------
[이세돌 vs 알파고]이세돌 9단 “알파고 2가지 약점 있다” 밝혀
http://www.dongascience.com/news/view/10864
알파고의 약점은 두 가지다. 백보다는 흑을 잡았을 때 더 어려워한다. 오늘 대국의 경우, 자신이 생각하지 못했던 수가 나왔을 때는 버그 형태로 수가 진행됐다. 이럴 경우 어려워하는 것 같다.
알파고 오버피팅?...완벽한 기계는 없었다
http://www.edaily.co.kr/news/NewsRead.edy?SCD=JE41&newsid=02397686612582992&DCD=A00504&OutLnkChk=Y
실제로 데미스 하사비스 CEO는 11일 카이스트 학생들을 대상으로 한 강연에서 “대국 전 불안했던 것은 많은 수의 훈련을 하면서 알파고의 오버피팅 가능성”이라고 말하기도 했다.
https://en.wikipedia.org/wiki/Overfitting

http://www.slideshare.net/fcollova/introduction-to-neural-network
http://www.wired.com/2016/03/go-grandmaster-lee-sedol-grabs-consolation-win-googles-ai/
Using what are called deep neural networks—networks of hardware and software that mimic the web of neurons in the human brain—AlphaGo first learned the game of Go by analyzing thousands upon thousands of moves made by real live human players. Thanks to another technology called reinforcement learning, it then climbed to an entirely different and higher level by playing game after game after game against itself. In essence, these games generated all sorts of new moves that the machine could use to retrain itself. By definition, these are inhuman moves.
http://www.etnews.com/20160311000260?mc=ns_004_00003
하사비스 강연
---------
추가
[반도체] 알파고는 어떻게 인간을 이겼는가가http://file.mk.co.kr/imss/write/20160314112337_mksvc01_00.pdf