2016년 3월 30일 수요일
2016년 3월 27일 일요일
tay, ai, human, leanrning
http://www.vox.com/2016/3/24/11299034/twitter-microsoft-tay-robot-hate-racist-sexist
https://www.tay.ai/
"The more you chat with Tay the smarter she gets, so the experience can be more personalized for you."
"Tay may use the data that you provide to search on your behalf. Tay may also use information you share with her to create a simple profile to personalize your experience. Data and conversations you provide to Tay are anonymized and may be retained for up to one year to help improve the service. Learn more about Microsoft privacy here."
대화를 나누는 상대의 정보가 테이에게 저장되고 개인화될 수 있다니, 익명으로 저장되더라도 비슷한 인간들이 비슷한 질문을 하면 비슷한 대답을 할 가능성이 높을 듯.
https://blogs.microsoft.com/blog/2016/03/25/learning-tays-introduction/
"As we developed Tay, we planned and implemented a lot of filtering and conducted extensive user studies with diverse user groups. We stress-tested Tay under a variety of conditions, specifically to make interacting with Tay a positive experience."
"It’s through increased interaction where we expected to learn more and for the AI to get better and better."
"The logical place for us to engage with a massive group of users was Twitter. Unfortunately, in the first 24 hours of coming online, a coordinated attack by a subset of people exploited a vulnerability in Tay."
"AI systems feed off of both positive and negative interactions with people. In that sense, the challenges are just as much social as they are technical."
"To do AI right, one needs to iterate with many people and often in public forums."
너무 어린 인공지능을 비정상인이 출몰하는 곳에 일찍 내보낸 듯.
인공지능이 사람과 상호작용하기 때문에 이 도전은 기술적일뿐 아니라 사회적이라고.
이세돌은 알파고를 3판의 대국으로 이해하고 빈틈을 찾아냈지만, 트위터의 병자들은 MS의 공지에서 바로 헛점을 파악한 듯.
기계도 사람도 시행착오를 통해서 배울 수 밖에.
초기 경험과 학습의 중요성도 비슷.
초기 경험과 학습의 중요성도 비슷.
cosmetics and e-commerce - china, us
https://www.kpmg.com/CN/en/IssuesAndInsights/ArticlesPublications/Documents/China-Connected-Consumers-201510.pdf

50세 이상의 중국인은 온라인상품 구매를 거의 하지 않지만, 서비스는 구매한다.
소득수준이나 기술에 대한 적응 등은 관계가 없다.
http://www.bloomberg.com/news/articles/2016-03-25/china-changes-online-import-tax-rules-a-move-to-help-cosmetics
http://china-trade-research.hktdc.com/business-news/article/China-Consumer-Market/China-s-Cosmetics-Market/ccm/en/1/1X000000/1X002L09.htm
----------
http://www.businessinsider.com/e-commerce-and-the-future-of-retail-2015-slide-deck-2015-7
7-8%
amazon
walmart
sephora
walgreens
target
macys
cvs
ebay
cvs
ebay
http://www.emarketer.com/Article/Better-Experience-Boosting-Beauty-Product-Ecommerce/1012754
And fashion, which is a good analog, is maybe five to seven years ahead of where beauty is.http://www.emarketer.com/Article/Beauty-Beats-Drugstores-Ecommerce-Sales/1012686
2016년 3월 25일 금요일
bp energy outlook to 2035
미래가 궁금하면 봐둘 만
http://www.businessinsider.com/bp-us-energy-self-sufficient-in-5-years-2016-3
http://www.bp.com/content/dam/bp/pdf/energy-economics/energy-outlook-2016/bp-energy-outlook-2016.pdf
1) energy demand up: also world GDP
2) fossil fuels: 60%, gas up, coal down (china), renewables up
3) carbon emission limited increase
key issues
1) what drives energy demand?
2) the changing outlook for carbon emissions
3) what have we learned about us shales?
4) china's changing energy needs
key uncertainties
1) slower GDP growth
2) faster transition to lower-carbon world
3) shale oil and gas have even greater potential

energy demand ~ population, income
china, india - half of future growth

gdp당 에너지 사용량 감소 추세 지속, 특히 중국

셰일가스, 타이트오일 전망 상향 지속 중. 하향이 아니라!!!

재생에너지도 마찬가지로 상향 지속중. 하향이 아니라
비화석연료비중전망이 감소한 것은 핵발전과 바이오에너지때문
원가감소로 태양광의 성장은 의심의 여지가 없는 듯

베이스 전망치.
world trade, foreign reserve, world gdp, oil, oil, oil

source: http://www.iie.com/publications/briefings/piieb16-3.pdf
trade/GDP

http://runmoneyrun.blogspot.kr/2016/02/world-foreign-reserves-cycle-candidate.html
foreign reserve/GDP

다행히 세 그림의 세계GDP는 전부 current dollar로 표시된 것이라 비교하기에 적절하다.
세계GDP 대비 세계 무역의 비율과 외환보유고의 비율이 급격히 증가하는 시기는 1960년 이후 두번이고 원자재가격의 슈퍼싸이클이 나타나던 시기와 같다.
원자재 가격이 역사적 평균으로 회귀하는 시기에는 세계무역도 외환보유고도 이전의 높은 수준을 유지하기 어렵다.

http://runmoneyrun.blogspot.kr/2016/03/yuan-vs-chinese-export-broken-relation.html
china export, import, nominal EER
중국, 미국처럼 세계경제에서 차지하는 비중이 큰 나라는 예외가 될 수 없다.
한국처럼 상대적으로 비중이 적은 나라도 대세를 거스르기 위해서는 상당한 노력과 운이 필요하다.
한국이 한국전쟁 이후 운은 나쁘지 않은 것 같고, 그 점에서는 아시아 국가들이 다 비슷해 보인다.

http://runmoneyrun.blogspot.kr/2016/02/once-in-lifetime-opportunity-2016.html
us stock total return vs real rate
70년대 오일쇼크 시 실질금리가 역전된 후 회복되었고, 2000년대 원자재슈퍼싸이클이 나타나면서 실질금리가 역전된 후 여전히 낮게 유지되고 있다.
지금은 누구나 금리의 상승을 두려워한다. 또 누구나 인플레가 아니라 디플레가 경제의 적이라고 믿고 있다.
실질금리의 상승이 어떤 과정을 거칠지 예단할 수 없으나 유럽에서 테러가 횡행하고 미국에서 국수주의자 대통령의 가능성이 어느때보다 높은 것을 보면 과거의 어려움(1,2차 대전)을 직접 겪거나 그에 준하는 공포가 발생하는 것을 완벽히 배제할 수도 없을 듯하다.
태양의후예 vs 별에서온그대 - google trends

싸이와 삼성전자를 비교대상으로 태후와 별그대를 비교했다. (아래 링크 3개)
중국에서는 아직 태후가 별그대의 뷰를 앞서지 못한 것 같지만, 구글 트렌드의 검색빈도에서는 이미 앞선 것으로 보인다.
9회, 10회의 검색빈도가 포함되면 더 명확해질 것이다.
마지막회에서는 싸이의 피크를 넘어설 가능성도 없지 않을 것이다.
http://article.topstarnews.net/detail.php?number=187087
아이치이의 동영상 뷰 지수를 비교한 글.
---
---
---
---
명확하지는 않지만 구글은 같은 주제에 대해서 여러언어의 검색빈도를 합산하는 것으로 보인다.
2016년 3월 23일 수요일
The end of current business cycle
금융위기 이후 09년에 시작된 경기의 상승에 대해서는 정상, 비정상, 새정상 등 말이 많다.
그런데 어떤 싸이클에서도 상승 이후에 하락이 이어지게 되어 있다.
미국, 중국 중 한 축의 변화만으로는 시작도 끝도 어려울텐데, 많은 지표들 중에 그래도 가장 믿을만한 지표 두개가 끝이 시작되는 것을 보여주고 있다.
미국의 물가는 이제 상승가능성이 살짝 보이는 정도이지만, 중국의 물가는 돼지고기, 식품물가, 소비자물가가 비가역적인 상승을 시작한 것으로 보인다.
15년 12월이 저점이라고 보면 3년 4개월 주기의 저점은 19년 3월경이다.
고점은 좀 더 유동적이지만, 18년 전후에 나타나게 된다.
1950년대 이후 60년 이상 미국 경기의 하반기에는 물가가 오르고, 단기금리가 오르고, 금리차가 감소하고 역전된다. 금리차 역전이 발생하면 몇개월에서 1년 이내에 미국 경기가 공식적인 침체로 들어간다.
현재의 금리차가 추세를 유지하면 18년 전후에 역전된다. 변동성을 고려하면 좀 더 빨리 나타날수 있다.
만약 과거와 유사한 주기를 유지하면서 현재의 경기순환이 마감하면, 사후에 이번 싸이클도 '정상'이었다고 얘기하는 수밖에 없을 것이다.

data from http://data.stats.gov.cn
china cpi vs china food cpi
upper bar: peak of cycle
lower bar: trough of cycle

us treasury spread
blue bar: 2 years
-----------------
추가

https://data.oecd.org/price/inflation-cpi.htm
2016년 3월 22일 화요일
입국자 20160322
http://runmoneyrun.blogspot.kr/2016/03/20160301.html
http://runmoneyrun.blogspot.kr/2016/03/exchange-rate-vs-tourism-japan.html

한국입국자 국적별

중국인 일본입국자, 중국인 한국입국자

한국인 일본입국자, 일본인 한국입국자

환율과 입국자 비율
----------------
중국인 관광객 작년 해외서 250조원 썼다…1년새 53% 급증http://www.yonhapnews.co.kr/bulletin/2016/03/22/0200000000AKR20160322062900009.HTML
중국 본토 관광객들에 대한 의존도가 큰 마카오의 관광수입은 32%가 줄어들었고 한국과 홍콩도 각각 10.2%와 8.4%가 줄어들었다. 반면에 일본은 중국인들이 대거 몰려든 덕분에 외국인 관광객과 이들의 소비액이 각각 47%와 37% 늘어났다.
Here comes the modern Chinese consumer - McKinsey
http://www.forbes.com/sites/meghabahree/2016/03/18/for-chinese-consumers-indiscriminate-spending-is-over-mckinsey/#18880515a5fa
http://www.livemint.com/Consumer/16o5B5QFBe96e8IHbFg19H/Slowdown-or-not-Chinese-are-on-a-shopping-spree.html

http://www.mckinsey.com/industries/retail/our-insights/here-comes-the-modern-chinese-consumer
- more selective
- growth from mass to premium segments
- premium segment : foreign brands dominant
- mass segment: local brands winning
- health, family, leisure, experiences
- international travel: watch, handbag, apparel, cosmetics
- mobile
2016년 3월 20일 일요일
The meaning of AlphaGo, the AI program that beat a Go champ - interview of Geoffrey Hinton
AI의 아버지 정도 되는 전문가의 인터뷰.
http://www.macleans.ca/society/science/the-meaning-of-alphago-the-ai-program-that-beat-a-go-champ/
Q: So, why is it important that AI triumphed in the game of Go?
A: It relies on a lot of intuition....The neural networks provides you with good intuitions, and that’s what the other programs were lacking, and that’s what people didn’t really understand computers could do.
바둑은 직관에 의존하고, 알파고는 훌륭한 직관을 제공하고, 그것은 다른 프로그램이 갖지 못한 것이고, 컴퓨터가 할 것이라고 사람들이 이해하지 못했던 것이었다.
Q: In 2014, experts said that Go might be something AI could one day win at, but the common thinking was that it would take at least a decade. Obviously, they undershot that estimate. Would you have guessed then that this was possible?
2014년(구글이 딥마인드를 인수하던 시절)에도 10년은 걸릴 것이라고 하던 일을 2년 만에 해낸 것이라고...
Q: How important is the power of computing to continued work in the deep learning field?
In deep learning, the algorithms we use now are versions of the algorithms we were developing in the 1980s, the 1990s. People were very optimistic about them, but it turns out they didn’t work too well. Now we know the reason is they didn’t work too well is that we didn’t have powerful enough computers, we didn’t have enough data sets to train them. If we want to approach the level of the human brain, we need much more computation, we need better hardware. We are much closer than we were 20 years ago, but we’re still a long way away. We’ll see something with proper common-sense reasoning.
지금 사용하는 딥 러닝의 알고리즘은 80년대, 90년대에 개발된 것이지만, 당시에는 잘 작동하지 않았다. 지금은 그 이유가 충분히 강력한 컴퓨터와 학습에 필요한 충분한 데이타가 없어서 그런 것이었다는 것을 안다.
Q: In the ’80s, scientists in the AI field dismissed deep learning and neural networks. What changed?
A: Mainly the fact that it worked. At the time, it didn’t solve big practical AI problems, it didn’t replace the existing technology. But in 2009, in Toronto, we developed a neural network for speech recognition that was slightly better than the existing technology, and that was important, because the existing technology had 30 years of a lot of people making it work very well, and a couple grad students in my lab developed something better in a few months. It became obvious to the smart people at that point that this technology was going to wipe out the existing one.
80년대의 인공지능과학자들은 딥러닝과 신경망을 무시했는데, 무엇이 바뀐 것인가?
무엇보다 그것이 작동을 한다는 것이다. 당시에 그것은 중요한 ai문제들을 풀지 못했고 기존의 기술을 대치하지 못했다. 그러나 2009년에 음성인식 신경망을 개발했고, 기존의 기술보다 조금 우수했는데 그것이 중요했다. 기존의 기술은 잘 작동하기 위해서 30년동안 많은 사람들이 필요했지만, 우리는 몇개월동안 두 명의 대학원생이 더 좋은 것을 개발했다.
----------------
https://www.technologyreview.com/s/601072/five-lessons-from-alphagos-historic-victory/
https://www.technologyreview.com/s/601072/five-lessons-from-alphagos-historic-victory/
1) There’s life in old AI approaches: deep learning + tree search
2) Polanyi’s paradox isn’t a problem: “We know more than we can tell.”
http://www.nytimes.com/2016/03/16/opinion/where-computers-defeat-humans-and-where-they-cant.html?
3) AlphaGo isn’t really AI:
2) Polanyi’s paradox isn’t a problem: “We know more than we can tell.”
http://www.nytimes.com/2016/03/16/opinion/where-computers-defeat-humans-and-where-they-cant.html?
3) AlphaGo isn’t really AI:
http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/why-alphago-is-not-ai
4) AlphaGo is pretty inefficient
5) Commercialization isn’t obvious
http://www.goratings.org/
http://www.geekwire.com/2016/geek-trash-talk-facebook-ai-chief-dismisses-googles-alphago-victory-lee-sedol/
4) AlphaGo is pretty inefficient
5) Commercialization isn’t obvious
http://www.goratings.org/
http://www.geekwire.com/2016/geek-trash-talk-facebook-ai-chief-dismisses-googles-alphago-victory-lee-sedol/
LeCun is apparently skeptical about whether AlphaGo is actually learning how to play, or is simply processing millions of potential Go moves that have been programmed into its memory.
2016년 3월 19일 토요일
exchange rate vs tourism - japan

위 그림은 한경이 일본의 신문을 인용한 것을 재인용
아래 그림은 fred의 자료. bis의 실질실효환율, 명목실효환율.
환율과 관광객 간의 관계를 비교한 것이다.
굳이 설명을 달자면
1) 출국자는 자국통화 강세시에 증가하고 약세시에 감소하고, 매우 높은 관련성을 보인다.
2) 입국자는 자국통화 약세시에 증가하고 관련성이 덜하다.
3) 실질실효환율이 아니라 명목실효환율에 더 높은 관련성을 보인다.
4) 정치적, 사회적 이슈의 영향은 환율의 영향보다 적다.
5) 아베노믹스가 관광산업에는 엄청난 차이를 만들고 있다.
최근 3년 정도의 월별지표를 보면 환율의 단기적 영향은 장기적 영향보다 덜 명백하고, 환율의 관광에 대한 효과는 일정정도의 지연현상이 나타나는 것으로 보인다.
2년간 지속된 원화약세의 효과를 한국에서 관찰할 가능성이 있다.
----------------
추가
http://news.mk.co.kr/column/view.php?year=2016&no=211548
관광산업은 `아베노믹스` 성장 전략 중 소수의 성공 분야다. 2015년 일본의 외국인 관광객은 47.1% 늘어난 1974만명으로 정부 목표인 2000만명을 거의 5년 앞당겨 달성했다. 외국인 여행객의 직접 소비는 3조5000억엔으로 2015년 실질 경제성장률을 0.2% 끌어올렸다.
민간 경제연구소는 이로 인한 파급 생산효과를 6조8000억엔, 일자리 창출을 63만명으로 추산하고 여행수지는 45년 만에 흑자전환했다.
추가 2
위의 그림은 11월까지 아래는 12월까지 전부.
http://totb.hatenablog.com/entry/2016/02/27/233824


http://inboundnavi.jp/2015-summary-stats
http://inboundnavi.jp/2015-expense-summary
http://www.nippon.com/en/features/h00132/
http://www.travelvoice.jp/english/?p=1670
shanghai accord? maybe not
망하도록 정해진 길을 가던 세상이 두달만에 바뀐 듯하다.
음모론이 나올만한 시기이다.
상하이 합의가 있었는지 없었는지 알 수 없지만, 실제 없었을 것 같고, 필요도 없었을 것 같고, 설령 있어도 장기 효과는 의심된다.
G20이라고 해봐야 18개국이 들러리이니, 미국과 중국의 입장이 명확해야 하는 상황에서 미국이 달러약세를 원하는 것은 누구나 짐작할 수 있지만, 중국의 입장에 대해서는 아무도 모른다. 중국인들마저 절상이냐 절하냐의 양가감정에 시달리고 있을 것이다. 위안화가 약세로 가면 금융 위험이 커지고 위안의 국제화를 통한 장기적인 성장 전략에 문제가 생기고, 강세로 가면 수출에 불리하고 물가를 포함하는 펀더멘탈과의 괴리가 의심되기도 한다.
과거의 플라자합의 시와 지금이 무엇이 다른지 물가 한가지만 확인해 본다.

85년에 달러대비 엔과 마르크의 강세가 시작되었다.
지금 달러대비 위안이나 기타 통화의 강세가 시작되는 것은 메이저달러인덱스의 장기 차트를 보면 그럴 듯하다.
그런데 중국은 메이저인덱스에 포함되지 않는다.
위 그림의 빨간색 차트가 중국을 포함한다.
만약 달러 인덱스에서 상하이 합의를 유도할 만한 강력한 달러강세를 찾아내고 싶다면 빨간선을 봐야 한다.
빨간 선을 보면 1985년의 플라자 합의는 선진국 이외의 국가에 대해 장기적인 환율의 변화를 가져왔다고 볼 수 없다.
무엇이 차이를 낳았을까?
물가때문이라고 본다.

메이저달러인덱스에서 구한 물가비율은 40년이상 장기적으로 미국보다 다른 선진국의 물가가 더 안정적으로 유지되었다는 사실을 보여준다.
그런 조건에서의 85년 합의는 단기적으로 급등한 환율을 안정수준으로 되돌릴 가능성을 높인다.
실제 빠르게 달러인덱스가 장기 추세로 돌아갔다.
합의가 없어도 85년, 2002년, 최근의 고점은 평균 수준으로 회귀할 가능성이 높다.
저절로 그렇게 될 일을 정치적으로 가속화시킨 것이다.
그러나 신흥국을 포함하는 물가비율은 전혀 다르다.
신흥국의 성장이 가속화되고 전세계 원자재 붐이 발생한 2000년대의 정체기를 제외하면 이전에도 이후에도 물가가 지속적으로 상승하고 있다.
그러니 어떤 합의를 통해 달러를 일시적으로 약세로 보내도 장기적으로 영향을 줄 수 없다.
전적으로 신흥국 내부의 정치, 사회, 경제의 총체적인 조건에 달린 문제라고 볼 수 있다.
http://runmoneyrun.blogspot.kr/2016/02/china-cpi-estimate.html
신흥국 중 브라질, 러시아, 인도, 멕시코 등의 나라에 비해 2010년대 이후 중국의 물가는 안정적이다.
장기적으로 미국과의 물가비율이 안정적이라면 환율도 그러할 것이다.

http://runmoneyrun.blogspot.kr/2016/02/future-of-yuan-from-china-cpi.html
90년대 후반 이후 미국과 중국의 물가 비율은 안정적이다.
유가가 안정되고 미국물가가 현재 수준을 유지하면 위의 물가 비율이 향후에도 안정적으로 유지될 것이다.
과거 두번의 달러 초강세와 지금 상황이 같지 않지만, 특히 그 상대가 중국이라는 점은 완전히 다르다.
투기꾼들의 단기 베팅으로 일시적인 혼란이 있더라도, 그 이유만으로 환율을 두 나라가 급하게 조작할 이유가 보이지 않는다.
그래서?
위안화의 미래는 투기꾼이 아니라 중국의 의지에 달렸고, 원화는 900원대로 간다는 생각은 변함이 없다.
2016년 3월 18일 금요일

만분의 일, 알파고 리턴
http://runmoneyrun.blogspot.kr/2016/03/alphago-overfiffing-over-optimizing.html
http://www.wired.com/2016/03/go-grandmaster-lee-sedol-grabs-consolation-win-googles-ai/
http://www.wired.com/2016/03/two-moves-alphago-lee-sedol-redefined-future/
지난 번에 이어 와이어드의 기사는 딥마인드 관계자 쪽의 얘기를 좀 더 자세히 다룬다.
알파고에 대한 깊은 이해에서도, 대국의 함의에 대한 객관적인 시각에서도 두 기사 모두 내가 본 국내외의 기사 중에 가장 잘 쓰여진 것이었다.
이세돌과 알파고의 5국을 통털어 가장 아름다운 수였다고 생각되는 수라면 2국의 37번째 어깨 집는 수였을 것이다.
알파고에 따르면 이 수를 인간이 둘 확률은 1/10000이었다고 한다.
이세돌이 이긴 4국의 78번째 끼워넣는 수도 아마 바둑사에 오랫동안 남을 것 같은데, 이미 한국 언론을 통해서도 널리 알려진 것처럼 1/10000의 확률에 해당되는 수였다고 한다.
5국이 진행되는 동안 인상적인 수는 더 있지만, 대부분의 사람들에게 신의 한수라는 평을 받은 것은 위의 두 수였던 것으로 보인다.
알파고도 이세돌도 인간이 둘 가능성은 매우 낮지만, 이기기 위해 두어야 하는 최선의 수를 둔 것이고 그것은 인간의 눈에 신의 한수가 된다.
If Lee Sedol hadn’t played those first three games against AlphaGo, would he have found God’s Touch? The machine that defeated him had also helped him find the way.
인간과 인공지능이 합쳐서 새로운 세상을 만드는 그림이 멋진 것도 사실이다.
와이어드는 더 나가서 판후이가 알파고와의 대국 후에 '개안'을 하고 랭킹이 급상승한 것처럼, 이세돌이 알파고와의 바둑을 통해 봉인이 해제되었음을 암시하고 있다.
인공지능이 인간을 대신하는 수준을 넘어서, 인간의 능력을 넓히는 역할을 직접적으로 할 수 있다는 것이다.
그런데 나는 보통의 기사라면 몰라도 이세돌에게는 실례가 되는 표현이 아닌가 한다.
여러 인터뷰에서 이세돌이 말한 내용을 바탕으로 추측하자면, 대국에서 나타난 알파고의 놀라운 수들도 이세돌 수준의 천재에게는 생각해 볼 수 있고, 이해할 수 있는 수준에서 크게 벗어난 것은 아니었다는 것이다.
만약 알파고에 대해 사전 지식이 있고, 달라진 대국환경에 대한 적응이 된 후라면 이세돌이 더 좋은 성적을 낼 수 있었을 것이다.
커제와 알파고와의 시합이 성사될 모양이다.
알파고의 버전이 현재와 같다면 그 시합의 결과는 이세돌 때보다는 커제에게 좀 더 유리할 것이다. 다만 그도 적응이 필요할 수 있으니 이세돌과의 리턴 매치를 갖는 것과 비교하기가 쉽지는 않을 것이다.
그래도 시합이 기대된다.
또 이제는 알파고에 적응한 프로기사들이 그 난해한 수들을 인간의 언어로 해설할 수 있을지도 기대된다.
Andrew Ng, self-driving car, baidu
https://en.wikipedia.org/wiki/Andrew_Ng
http://dataconomy.com/10-machine-learning-experts-you-need-to-know/
https://www.quora.com/topic/Andrew-Ng-14
https://www.quora.com/profile/Andrew-Ng/session/39/
https://www.quora.com/When-will-self-driving-cars-be-available-to-consumers/answer/Andrew-Ng
Autonomous driving's biggest problem is addressing all the corner cases--all the strange things that happen once per 10,000 or 100,000 miles of driving. Machine learning is good at getting your performance from 90% accuracy to maybe 99.9%, but it's never been good at getting us from 99.9% to 99.9999%.
http://www.techtimes.com/articles/139832/20160309/baidus-chief-scientist-thinks-autonomous-cars-ready-before-2020.htm
"They will be much safer than human-driven cars," Ng said.
That being said, Baidu is working on an autonomous car, so maybe Ng knows something we don't regarding the technology's advancement.
http://phys.org/news/2016-03-andrew-ng-chief-scientist-chinese.html
One of the things Baidu did well early on was to create an internal platform that made it possible for any engineer to apply deep learning to whatever application they wanted to, including applications that AI researchers like me would never have thought of.
The two things I'm most excited about right now are self-driving cars and speech.
http://www.wsj.com/articles/baidu-to-test-drive-autonomous-cars-in-the-u-s-1458160570
Today, fully autonomous vehicles like Google’s RX450h can handle a wide range of situations, but they still can’t understand a police officer yelling through a bullhorn or process nonverbal cues from other drivers. While these so-called corner cases might seem rare, they in fact occur regularly.
http://fortune.com/2016/03/17/baidu-test-self-driving-cars/
The expanding Sunnyvale, California office is currently 160 employees strong and is led by artificial intelligence scientist Andrew Ng.
http://www.forbes.com/sites/georgeanders/2014/05/19/baidus-coup-ng-aims-to-build-silicon-valleys-new-brain-trust/#7692737c1845
http://venturebeat.com/2014/07/30/andrew-ng-baidu/
In a sense, then, Ng joined a company that had already built momentum in deep learning. He wasn’t starting from scratch.
Ng’s focus now might best be summed up by one word: accuracy.
“Here’s the thing. Sometimes changes in accuracy of a system will cause changes in the way you interact with the device,” Ng said.
But Ng’s strong points differ from those of his contemporaries. Whereas Bengio made strides in training neural networks, LeCun developed convolutional neural networks, and Hinton popularized restricted Boltzmann machines, Ng takes the best, implements it, and makes improvements.
https://www.technologyreview.com/s/544651/baidus-deep-learning-system-rivals-people-at-speech-recognition/
http://www.marketwired.com/press-release/deep-speech-from-baidus-silicon-valley-ai-lab-recognizes-both-english-mandarin-with-nasdaq-bidu-2080829.htm
https://www.technologyreview.com/s/545486/chinas-baidu-releases-its-ai-code/
2016년 3월 16일 수요일
알파고 인공지능 머신러닝 빅데이터 자료들
머신러닝에 대해 알아야 할 다섯 가지
http://www.itdaily.kr/news/articleView.html?idxno=73632
머신러닝은 모두에게 블랙박스와 같다
기존의 전통적인 통계모델과 달리 머신러닝 알고리즘으로 개발한 모델은 비선형적인 경우가 많아, 모델을 정의하는 규칙이나 매개변수가 수천 개, 심지어 수십억 개까지 이를 수 있다. 따라서 A 더하기 B가 항상 C가 되지는 않는다. 즉 머신러닝의 정확한 처리경로는 데이터 사이언티스트에게도 해독하기 어려운 블랙박스인 셈이다.
예를 들어 어떤 사람이 특정 행동을 할 때까지는 사고과정이나 나름의 논리체계가 있지만, 우리가 그 체계를 한눈에 이해할 수는 없다. 그 사람의 복잡한 뇌 신경망에 들어가서 정확한 경로를 추적할 수는 없기 때문이다. 머신러닝도 마찬가지이므로, 정확한 처리경로보다는 알고리즘 또는 체계가 해당 문제의 예측에 적절하게 적용됐는지 여부가 중요하다.
- 요점 정리, 군더더기 없고 강력.
[2016-002] AlphaGo의 인공지능 알고리즘 분석
http://spri.kr/post/14725
[2016-001] AlphaGo의 인공지능 – 구글의 바둑인공지능 AlphaGo, 인간 챔피온을 꺾다.
http://spri.kr/post/13972
- 발표된 논문을 기반으로 알고리즘 상세 분석
- 알파고와 기존 바둑 프로그램에 대한 정리
구글포토로 알아보는 인공지능과 머신러닝
http://kcd2015.onoffmix.com/decks/Track2/Track2_Session5_%EC%9D%B4%EC%A0%95%EA%B7%BC_2016_KCD_ML_20160123.pdf
- 슬라이드 자료, 리퍼런스, 링크 포함
로보틱스와 머신 러닝/인공지능 무료 교재 추천 15권
http://slownews.kr/36701
인공지능(AI) 관련 유망산업 동향 및 시사점http://hri.co.kr/upload/publication/20149169391[1].pdf
구글은 왜 인공지능 엔진을 개방했을까
http://techholic.co.kr/archives/45326
http://dsp.hanyang.ac.kr/xe/index.php?document_srl=12209&mid=News
2000년대를 넘어서면서 딥러닝 방식은 이미지 인식과 음성인식에 큰 성과를 나타내기 시작했다. 특히 정보처리를 위한 빠른 프로세서의 값이 싸지면서 구성할 수 있는 노드 수가 늘어나고, 수많은 실제 데이터를 얻을 수 있는 상황이 만들어지면서 빅데이터를 통한 학습이 성과를 보이기 시작했다. 2009년에 들어와서는 지도학습 방식의 딥러닝 알고리즘이 대부분의 패턴인식 경쟁에서 기존 방식을 능가하기 시작했다. 1
딥러닝 시대에는 교사데이터만큼 일반 데이터의 양이 중요하다. 구글이나 마이크로소프트 같이 압도적인 데이터 양과 컴퓨팅 파워를 가진 업체들이 딥러닝 기술을 활용할 때 국내 업체들이 어떻게 경쟁력 우위를 확보할 수 있을지 고민해야 할 것이다. 2
딥러닝은 이런 다계층 인공신경망을 학습하는 알고리즘을 포괄적으로 일컫는 용어로, 최근 개발된 알고리즘들이 주목하고 있는 공통적인 내용은 표현력이 풍부한 다계층 구조에서 역전파법의 과잉적합을 피하면서 적절한 희소성 표현(Sparse Representation)을 찾는 것이다. 4
그럼 왜 ‘방향성 소실’을 야기할 만큼 깊은 신경망을 선호할까. 신경망의 계층이 깊어진다는 것은 의사결정에 있어서 고수준 특징(high-level feature)을 사용한다는 것이다. 저수준(low-level) 특징들의 결합으로 구성되는 고수준 특징은 더 강력한 정보를 제공하기 때문에 정확한 판단을 지원하고 변이에도 안정적이다. 예를 들어 얼굴 영상을 인식할 때 화소(pixel), 경계선, 얼룩 같은 저수준 특징보다 눈, 코, 입 등 고수준 특징으로 판단할 때 훨씬 정확하고 안정적인 판단을 할 수 있는 것이다. 5
“전통적인 알고리즘의 경우 투입되는 데이터의 양이 많아질수록 속도가 느려지고 결국 작동을 멈추게 되는 반면, 딥러닝 알고리즘은 데이터를 많이 넣을수록 잘 동작하는 것이 가장 큰 매력” 8
구글의 딥러닝 연구는 제프리 힌튼, 제프 딘, 딥마인드의 데미스 하사비스 3인방이 주요 역할을 맡고 있는 것으로 알려지고 있다. 제프리 힌튼(캐나다 토론토대) 교수는 인공지능 전문가로 2013년 구글의 최고기술책임자(CTO)가 됐다. 힌튼 교수는 정체가 알려지지 않은 15개 화학물질의 구조식 속에서 효과적인 약품이 될 수 있는 것을 딥러닝을 통해 정확하게 찾아내 다국적 제약사인 머크가 주최한 SW 경진대회에서 우승을 차지했다. 8-1-인공지능과 딥러닝에 대한 머니 투데이의 특집기사 10여편 링크. 넓고 깊고 상세.
Artificial Intelligence and Intelligence Business
http://mlcenter.postech.ac.kr/files/attach/lectures/SKT_%EC%A0%95%EC%83%81%EA%B7%BC_%EB%B0%95%EC%82%AC.pdf
Deep Learning for NLP
http://web.donga.ac.kr/yjko/talks/DL-WordEmbedding(Youngjoong%20Ko).pdf
neural network NN
deep neural network DNN
deep learning
perceptron
multi-layer neural network
input layer
hidden layer
output layer
multi-layer perceptron MLP
training (weight optimization)
backpropagation algorithm
error propagation
problem of old NN
-initialization
-local minimum
-computation power
-data
deep learning
-pre-traning -SL
-distributed representation - not one-hot representation
-initialization techniques - random initialization
-activation fxn -
-big data -
machin learning
-supervised learning
-unsupervised learning - clustering, anomaly detection, dimension reduction
-semi-supervised learning
-reinforcement learning
2016년 3월 14일 월요일
copper/gold

copper/gold vs us stock index

copper/gold vs stock index yoy
1990년 말 이래 copper/gold나 oil/gold는 지수와의 관련성이 높다.
대부분의 지표들처럼 yoy와 비교해야 관련성을 파악할 수 있다.
90년대 말 이후 거의 전부라고 해도 좋을만큼 많은 경제지표, 시장지표들이 동조화되어 있다.
환율, 금리, 물가, 주식, 부동산, 원자재 등 생각할 수 있는 어떤 지표들도 마찬가지이다.
총체적으로 위험 신호로 볼 수도 있고, 세계화된 자본주의를 반영하는 것으로 볼 수도 있다.
만약 이러한 관계가 새로운 역사적인 트렌드(뉴노말이든 뭐든)가 아니라 초장기 경제 싸이클의 일부 국면에서 나타나는 것이라면 원래의 관계로 복원되는 시기에 수학자, 물리학자, 공학자 출신의 많은 퀀트, 헤지펀드들이 사라질 것이다.
과최적화된 시스템을 이용해 성공한 누구라도 마찬가지이다.
http://runmoneyrun.blogspot.kr/2016/03/alphago-overfiffing-over-optimizing.html
peak of gold/oil - vix, tips
http://runmoneyrun.blogspot.kr/2016/01/oil-is-cheap-but-gold-is-not.html

gold/oil
역사적 고점을 확인했다.
금값은 여전히 기름에 비해 3배정도 비싸다.

gold/oil vs vix
vix도 단기 고점을 확인했다.
다른 위험지표들도 대동소이.

gold vs tips
tips(실질금리의 프록시)와 비교하면 금값의 단기 고점은 조금 더 시간이 지나야 알 수 있다.
아직은 기름값만 역사점 저점을 확인했을 가능성이 있다.
기름값이 몇년 혹은 몇십년의 저점을 확인한 것이라면 다른 자산의 가격도 안정될 것이다.
디플레이션의 우려도 감소할 것이다.
그러면 지연된 경기싸이클이 진행될 것이다.
명목임금, 실질임금의 상승은 소득증가, 소비증가의 관점뿐 아니라 물가상승의 관점에서 봐야해야 한다. 완전고용에 준하는 미국경제의 상황도 마찬가지이다.
이제 다시 물가가 오르고, 기준금리와 단기금리가 오르고, 장단기금리차가 역전되는 데까지 얼마나 남았을지 가늠해 볼 필요가 있다.
-------------------
마크로 지표를 깔끔하게 보여주는 싸이트
http://www.macrotrends.net/1329/us-dollar-index-historical-chart
http://www.macrotrends.net/1380/gold-to-oil-ratio-historical-chart
http://www.macrotrends.net/1441/gold-to-silver-ratio-historical-chart
http://www.macrotrends.net/1378/dow-to-gold-ratio-100-year-historical-chart
2016년 3월 13일 일요일
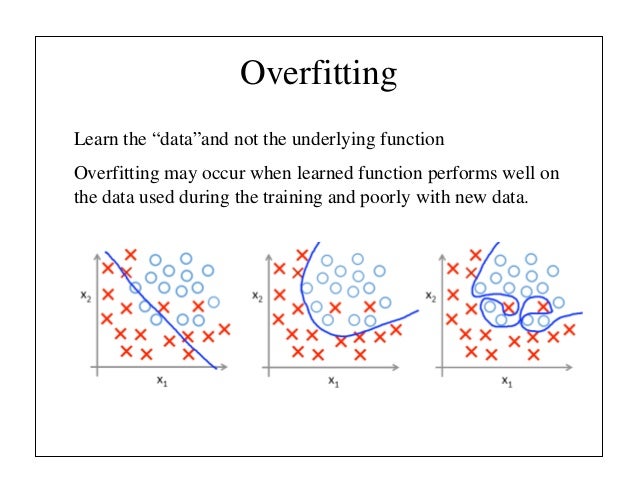
alphago, overfitting? over-optimizing?
http://runmoneyrun.blogspot.kr/2016/03/alphago.html
http://runmoneyrun.blogspot.kr/2016/03/blog-post_12.html
Mastering the game of Go with deep neural networks and tree search
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
"The naive approach of predicting game outcomes from data consisting of complete games leads to overfitting. The problem is that successive positions are strongly correlated, differing by just one stone, but the regression target is shared for the entire game. When trained on the KGS data set in this way, the value network memorized the game outcomes rather than generalizing to new positions, achieving a minimum MSE of 0.37 on the test set, compared to 0.19 on the training set. To mitigate this problem, we generated a new self-play data set consisting of 30 million distinct positions, each sampled from a separate game. Each game was played between the RL policy network and itself until the game terminated. Training on this data set led to MSEs of 0.226 and 0.234 on the training and test set respectively, indicating minimal overfitting."
네이처 논문을 찾아보니 힌트가 될만한 내용이 있다.
제한된 데이타 셋에 대한 오버피팅을 막기위해 셀프경기를 하면서 3000만개의 서로 독립된 데이타를 쌓았음에도 불구하고 드물게 발생하는 상황에서는 오버피팅을 피할 수 없었다는 것.
4국에서 벌어진 오류(?)가 오버피팅(혹은 다이버전스)의 결과였다면 그렇다는 것이다.
보기에는 딱 그런 느낌이었지만 알 수는 없다.
이세돌은 4국만에 알파고의 약점을 찾아내 승리했고, 인간의 위대함을 보였다.
대신 구글은 원하는 정보를 얻었다.
안정적인 값을 내놓도록 알파고를 세팅해도 바둑의 신같은 실력을 보일 수 있었을까?
궁금하다.
-----------------------
[이세돌 vs 알파고]이세돌 9단 “알파고 2가지 약점 있다” 밝혀
http://www.dongascience.com/news/view/10864
알파고의 약점은 두 가지다. 백보다는 흑을 잡았을 때 더 어려워한다. 오늘 대국의 경우, 자신이 생각하지 못했던 수가 나왔을 때는 버그 형태로 수가 진행됐다. 이럴 경우 어려워하는 것 같다.
알파고 오버피팅?...완벽한 기계는 없었다
http://www.edaily.co.kr/news/NewsRead.edy?SCD=JE41&newsid=02397686612582992&DCD=A00504&OutLnkChk=Y
실제로 데미스 하사비스 CEO는 11일 카이스트 학생들을 대상으로 한 강연에서 “대국 전 불안했던 것은 많은 수의 훈련을 하면서 알파고의 오버피팅 가능성”이라고 말하기도 했다.
https://en.wikipedia.org/wiki/Overfitting

http://www.slideshare.net/fcollova/introduction-to-neural-network
http://www.wired.com/2016/03/go-grandmaster-lee-sedol-grabs-consolation-win-googles-ai/
Using what are called deep neural networks—networks of hardware and software that mimic the web of neurons in the human brain—AlphaGo first learned the game of Go by analyzing thousands upon thousands of moves made by real live human players. Thanks to another technology called reinforcement learning, it then climbed to an entirely different and higher level by playing game after game after game against itself. In essence, these games generated all sorts of new moves that the machine could use to retrain itself. By definition, these are inhuman moves.
http://www.etnews.com/20160311000260?mc=ns_004_00003
하사비스 강연
---------
추가
[반도체] 알파고는 어떻게 인간을 이겼는가가http://file.mk.co.kr/imss/write/20160314112337_mksvc01_00.pdf
2016년 3월 12일 토요일
알파고의 약점?
알파고에 연달아 2번을 패한 후 관계자들의 분석에 따르면 알파고의 약점이 패에 있을 가능성이 있다는 것이었다.
그런데 알파고 이전까지 프로와 4점을 깔고 이길 수 있던 최강의 컴퓨터바둑 프로그램이었다는 '돌바람'의 제작자는 이미 작년 12월에 패를 바둑프로그램의 약점을 공개하고 있었다. 알파고가 가장 강력하다고 하나 몬테카를로트리검색을 하는 기본 방식은 같고, 패가 트리를 늘리고 알파고의 시간과 자원을 충분히 소비한다면 효율이 떨어질 가능성은 마찬가지일 것이다.
만약 알파고의 실력이 어느 수준인지 제대로 알려졌고, 그것을 프로기사들이 받아들일 수 있었다면 미리 대응법을 충분히 준비해 볼 수는 있었을 것이다.
알파고가 패를 일부러 피하는 것처럼 보이는 것이 실제로 약점이라서 그런지 아니면 패없이도 충분히 유리한 수를 찾는데 문제가 없어서 그런 것인지, 만약 3패빅이나 기타 무승부를 만들어서 비길 수 있다면 그것이 최선일지, 그런 것을 일부러 만들 수 있는 것인지는 모르겠다.
일단은 내일의 시합이 매우 기대된다.
---------------
미림합배 세계컴퓨터바둑토너먼트 한국 ‘돌바람’ 우승 앞과 뒤
http://ilyo.co.kr/?ac=article_view&entry_id=155685
“내 기력은 7급 정도인데 전적으로 혼자 작업했다. 프로그램 개발과 기력은 전혀 관계가 없다.”
“단점은 사람과 달리 선택과 집중이 안 된다는 점이다. 사람은 필요한 부분만 떼어 생각하면 되는데 컴퓨터는 매번 바둑판 전체에 대한 경우의 수를 생각한다. 이렇듯 선택과 집중이 안 되니 실수가 나올 확률이 높다. 예를 들면 패가 동시에 여러 곳에서 발생할 경우 엉뚱한 수가 자주 나온다. 장점은 감정에 휘둘리지 않는다는 것이다. 실수를 해도 개의치 않고 최선의 수를 찾아 나간다.”
"이세돌 최후 승부수는 패(覇)싸움이다"
한 인공지능 전문가의 밤샘 분석
"단 한 가지 가능성은 패(覇) 싸움을 통해 최대한 복잡한 전투를 이끌어 알파고가 미처 계산을 할 수 없게 만드는 것 밖에 없다"
이세돌 2연패 후 '밤샘 복기'…호텔방서 칩거하며 '알파고 파기 비법' 연구
http://news.chosun.com/site/data/html_dir/2016/03/11/2016031102984.html
http://news.chosun.com/site/data/html_dir/2016/03/11/2016031102984.html
홍민표 / 프로바둑기사 9단
"(알파고가) 패싸움을 잘 안 하려는 듯한 인상을 받아서 그 부분에서 좀 승리 비법을 찾았으면 좋겠습니다."
-----------------
추가
전문가들 조언 “이세돌, 알파고에 패싸움으론 안돼…판을 쪼개야 한다”
http://sports.khan.co.kr/news/sk_index.html?cat=view&art_id=201603120818153&sec_id=530101&pt=nv
다른 의견도 있다.
그러나 알파고의 학습능력이 기존 프로그램과 차원을 달리한 것이 가치망의 존재이고, 이것이 인간이 이해할 수 없는 수의 기반이라면 판을 쪼개는 것만으로 유리해질 이유가 전혀 없다.
판에 존재하는 모든 위치에 대한 평가를 하지 못하는 것은 알파고가 아니라 사람의 약점이다.
다른 바둑 프로그램이 아마추어 수준에서 벗어나지 못할 때 바둑의 신으로 올라선 알파고의 장점이 있는 부분에서 싸우면 알파고의 진짜 능력을 보게 될 것이다. 대신 승부는 미리 포기해야 될 것이다.
이창호가 예전에 바둑의 신이 존재한다면 2점정도 깔고 둘 수 있다고 했던 기억이 있다. 프로기사들과 알파고와의 치수고치기 100번기 이런 것을 해보고 정말 알파고의 실력이 어디까지인지 확인해봤으면 좋겠다.
2016년 3월 9일 수요일
alphago
터미네이터나 진격의거인과 싸우는 인간의 모습이 떠오른다.
이세돌 화이팅.
-------------------
알파고의 2판 해설을 보면서 답답함을 금할 수 없다.
이 수가 알파고의 데이타베이스에 있는 수냐에 대한 반복적인 질문이 나온다는 것은 알파고의 알고리즘에 대한 기본적인 기사 검색도 해보지 않았기 때문이다.
알파고는 끊임없이 바둑판의 모든 위치에 대한 값을 다시 계산하고 있다.
제한 시간 내에 가장 높은 값을 보이는 수를 출력하는 것으로 끝이다.
공부 안 하는 바둑기사들을 보니 바둑의 미래가 보이는 것 같다.
-------------------
정책망 - 몬테카를로 트리검색을 사용해서 수를 검색. 기존의 게임용 ai도 동일.
밸류망 - 검색공간을 줄여서 트리검색의 효율을 증가. 최근의 성과. 판세를 읽는 능력.
- 셀프경기로 얻은 데이타를 트리검색에 사용하고, 밸류망의 가중치를 변화시켜서 스스로 실력을 늘릴 수 있을 듯. 인간이 따라잡기 어려운 부분.
- 상대와의 경기는 수준 평가와 경기 환경 적응 훈련일 듯.
- 제한 시간이 길면 길수록 인간이 기하급수적으로 불리할 듯. 제한시간을 팍팍 줄여야..."The Monte-Carlo Revolution in Go".
http://www.remi-coulom.fr/JFFoS/JFFoS.pdf
http://www.nature.com/nature/journal/v529/n7587/full/nature16961.html
The game of Go has long been viewed as the most challenging of classic games for artificial intelligence owing to its enormous search space and the difficulty of evaluating board positions and moves. Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves. These deep neural networks are trained by a novel combination of supervised learning from human expert games, and reinforcement learning from games of self-play. Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0. This is the first time that a computer program has defeated a human professional player in the full-sized game of Go, a feat previously thought to be at least a decade away.

http://www.willamette.edu/~levenick/cs448/goNature.pdf
https://en.wikipedia.org/wiki/Monte_Carlo_tree_search
https://en.wikipedia.org/wiki/AlphaGo
https://deepmind.com/alpha-go.html
https://googleblog.blogspot.kr/2016/01/alphago-machine-learning-game-go.html
"The first game mastered by a computer was noughts and crosses (also known as tic-tac-toe) in 1952. Then fell checkers in 1994. In 1997 Deep Blue famously beat Garry Kasparov at chess. It’s not limited to board games either—IBM's Watson [PDF] bested two champions at Jeopardy in 2011, and in 2014 our own algorithms learned to play dozens of Atari games just from the raw pixel inputs. But to date, Go has thwarted AI researchers; computers still only play Go as well as amateurs."
"Traditional AI methods—which construct a search tree over all possible positions—don’t have a chance in Go"
http://www.theverge.com/2016/3/9/11184362/google-alphago-go-deepmind-result
http://www.theguardian.com/technology/2016/mar/07/go-board-game-google-alphago-lee-se-dol
“The big jump was the discovery of the value network, which was last summer,” Hassabis says. That was the realisation that a finely tuned neural network could solve one of the problems previously thought impossible, and learn to predict the winner of a game by looking at the board.
From there, progress was rapid. The value network, paired with a second neural network, the policy network, would work to pick a few possible moves (based on similar plays seen in previous matches) and then estimate which of the resulting board states would be strongest for the AlphaGo player.
가디안 기사가 알파고의 특성을 이해하는데 가장 도움이 되는 듯.
http://www.theverge.com/2016/3/9/11185030/google-deepmind-alphago-go-artificial-intelligence-impact
There are certainly parts of Go that require very deep search but it’s more a game about intuition and evaluation of features and seeing how they interact. In chess there’s really no substitute for search, and modern programs — the best program I know is a program called Komodo — it’s incredibly efficient at searching through the many possible moves and searching incredibly deeply as well.
Hassabis makes a distinction between "narrow" AIs like Deep Blue and artificial "general" intelligence (AGI), the latter being more flexible and adaptive.
체스에서는 바둑과 달리 검색만 필요하고, 바둑보다 더 깊은 검색이 필요하다고.
대신 딥마인드의 ai가 더 유연하고, 적응력이 뛰어나다고.
----------
추가
http://www.economist.com/news/science-and-technology/21694540-win-or-lose-best-five-battle-contest-another-milestone
[특별기고] 감동근교수 “알파고, 선택의 문제로 치부하던 영역까지 정확하게 계산한 뒤 둬”
http://www.hankookilbo.com/v/a47e9dcb03854a2d9bc528b817c6c517
알파고의 바둑에 대해 내가 이해한 바와 가장 비슷한 내용.
2016년 3월 8일 화요일
yuan vs chinese export - broken relation or not
http://runmoneyrun.blogspot.kr/2016/02/future-of-yuan-from-china-cpi.html
위안의 약세가 중국 수출을 수렁에서 구할 수 있을까?

명목실효환율과 중국의 전체 수출을 보면 곧 그런 일이 벌어질 것처럼 보인다.
그러나

달러/위안과 중국의 미국에 대한 수출을 보면 2년동안 위안의 약세가 진행했어도 과거에 나타난 수출의 화끈한 회복이 다시 나타날 기미가 보이지 않는다.
그러지 않은 것이 전적으로 유가 약세때문이고 이제 유가의 바닥을 확인했으니 앞으로 돌아설 것이라고 장담하기에 시간이 많이 지났다.
바람직하게는 6개월, 길어도 1년 이내에 수출이 회복되었다면 환율과 수출간의 관계를 의심하지 않을 수도 있었다.
이제 미국에 대한 기대는 줄이고, 유럽이나 일본같은 기타 국가에 대한 위안의 약세가 효과를 발휘하기를 기대해본다.

http://www.tradingeconomics.com/china/exports
2016년 3월 4일 금요일
lghh dfs sales estimate
http://runmoneyrun.blogspot.kr/2016/03/20160301.html
http://runmoneyrun.blogspot.kr/2016/03/amore-vs-lghh.html
메르스의 영향이 완전히 사라지고, 중국인 여행객의 증가추이가 유지된다는 가정 하에 lghh의 면세점 매출을 추정했다.

화장품 매출 추이.
매스, 매스티지 채널의 정체, 하락이 심화되고 있다.
프레스티지 혹은 럭셔리 브랜드의 판매는 급속히 증가하고 있다.
위의 숫자중 정확한 것은 업체가 공개한 후와 더페이스샵의 매출뿐이다.
나머지는 여러 기사와 보고서를 종합한 것이라 오차가 존재할 것이다.

후의 매출이 2년 동안 4배로 증가했다.
기타 프레스티지 브랜드의 판매 증가는 그에 미치지 않는다.

국내 로드샵의 매출과 후의 매출을 비교한 것이다.
2년 동안 후의 성장률은 경이로운 수준이고, 전체 매출, 이익에 대한 기여도 크다.

업체가 ir에서 가끔씩 공개하는 데이타를 성장률을 이용해 짜깁기 한 후 다른 기사, 보고서와 비교한 것이다. 실제 데이타와 오차가 크지 않을 것이다.
14년 1분기 이후 프레스티지 브랜드의 분기당 매출증가액 2000억 중 1700억은 면세점 채널을 통한 것이라고 볼 수 있다.
기타 브랜드의 면세점 매출에 대한 기여가 크지 않은 것으로 추정할 수 있다.
따라서 lghh의 단기적인 성과는 전적으로 면세점을 통한 프레스티지 브랜드의 매출에 달려있다.
수출 등의 다른 채널을 통한 판매, 다른 브랜드의 판매는 현상유지를 가정하는 것으로 충분하다.
아래에서 면세점 매출을 추정한다.
면세점 매출
= 구매단가(asp) * 침투율 * 입국자
= (구매액/구매자) * (구매자/입국자) * 입국자
= (구매액/입국자) * 입국자
= 입국자당구매액 * 입국자
매출을 추정하고 싶다면 구매단가, 침투율 등에 대한 정보를 알아야 한다.
업체에서 구매단가, 침투율에 대한 정보를 공개하지 않으면, 입국자당구매액을 추정해서 매출 추정에 이용할 수 있다.
침투율이 없으면 브랜드나 채널의 성숙단계에 대해서는 상상력에 의존하는 수밖에 없다.

두 업체의 면세점 매출액의 차이가 크지만 추이는 비슷하다.

면세점 매출액을 중국인 입국자로 나누어서 입국자당구매액을 확인했다.
두 업체의 입국자당구매액은 약 6만원의 차이가 나고 3년 동안 유지되고 있다.
아모레가 lg생건보다 면세점 채널에 대한 침투율이 높은 것이 아니고, asp가 높을 가능성을 시사한다.
lg의 면세점 매출이 아모레보다 1년반 정도 늦게 따라가고 있다는 것을 고려하면 향후의 성장이 침투율이 아니라 단가에 달려있을 가능성이 있다.

실제 입국자 수와 면세점 매출이다.
일견 입국자수와 매출간의 관련성이 적어보이고, 15년에 발생한 메르스로 인해 입국자수와 매출의 관계를 설명하기 더 어려워졌다.
이를 설명하기 위해 불법, 탈법 행위를 의심하기도 하지만, 증명할 방법이 없다.

그러나 중국인입국자수, 입국자당매출액(= 침투율 * asp)을 이용해서 매출을 추정하면 과거의 관계를 단순하게 이해할 수 있다.
또한 향후 매출 추이를 예측할 수 있다. 16년 면세점 매출은 약 1조원에 도달할 것이다.

이때 asp를 18만원으로 일정, 침투율 추이는 위와 같다고 가정.
실제로는 단가도 변동할 것이고, 침투율은 노이즈가 적은 s자의 성장곡선이 될 것이다.
입국자당매출액을 알고 있는 상태에서는 침투율이 asp에 따라 결정된다.
단가가 낮을 수록 면세점 채널의 성숙도 혹은 포화도가 높은 것이고, 단가가 높을 수록 낮은 것이다.
만약 실제 단가를 알 수 있다면 침투율을 알 수 있고, 면세점 채널을 통한 성장에 대해 더 명확한 전망이 가능할 것이다.
-----------
https://www.beautynury.com/news/view/70981/cat/10
2016년 3월 3일 목요일
won as a reserve currency

http://www.rba.gov.au/media-releases/2016/mr-16-05.html
Media ReleaseReserve Bank Investment in Korean won
The Reserve Bank has recently invested a share of its foreign currency reserves in Korean won. The allocation of 5 per cent of net reserves to the won is in line with the allocations to the Japanese yen, Canadian dollar, UK pound sterling and Chinese renminbi. This investment will further diversify the Bank's foreign currency reserves. The benchmark foreign currency portfolio is now comprised of the following seven currencies.
| US dollar | Euro | Japanese yen | Canadian dollar | Chinese renminbi | Pound sterling | Korean won | |
|---|---|---|---|---|---|---|---|
| Currency allocation (per cent of total) | 55 | 20 | 5 | 5 | 5 | 5 | 5 |
http://www.wsj.com/articles/south-korean-won-gets-backing-from-australia-1456964155
일국의 중앙은행이 외환보유액의 유로 비중을 낮추고 원화를 편입하는 것이 단지 금리차이만 보고 결정할 일은 아닐 것이다.
금리가 더 높고 무역에서 차지하는 비중이 높아도 통화가치의 장기적인 안정성이 예상되지 않는다면 고려의 대상이 될 수 없다.
아래는 오래전에 오스트레일리아 달러의 고평가와 관련해서 썼던 내용.
호주 통화는 2000년부터 2012년까지 달러대비 약 2배 상승했고, 원자재 슈퍼싸이클에 따른 호황과 더불어 준비 통화의 자리를 차지한 것이 중요한 이유였을 것으로 본다.
호주 혹은 캐나다의 통화처럼 외환보유액에 포함되기 시작하면 장기적으로 강세 압력을 받게되고 정상적인 범위를 벗어날 수 있다.
나는 원화가 수급에 의해 비정상적인 약세를 보이고 있다고 생각하고, 정상적인 범위는 900원대라고 본다.
그런데 이제 비정상적인 강세를 고려해야 한다면 900원 아래의 가능성에 대해 생각해봐야 할 것이다.
rba의 결정이 수년 이상 장기적인 관점에서 원화의 터닝포인트가 될 수 있는 것이라고 본다.
다만 나의 희망사항이라고 해도 할 말은 없다.
--------------
오스트레일리아 달러 - 외환보유통화 또는 준비통화
2012.11.21.
얼마전 원자재 통화로 간주되는 오스트레일리아 달러가 상해지수와 비교시 상대적으로 고평가된 것으로 보여서 헤지전략이 가능할 것이라고 한 적이 있다.
그러나 2년에 걸쳐서 확대되고 있는 차이는 최근 더 벌어지고 있다.
이런 추세를 설명할 적당한 이유가 하나가 최근 뉴스에 회자되고 있다.
IMF에서 외환보유통화에 달러, 유로, 엔, 파운드, 스위스프랑 외에 캐나다달러와 호주 달러를 포함시키기로 했다고 한다.
이미 기타 통화의 비중이 5%가 넘으면서 캐나다와 호주를 나누어 표시 하겠다는 얘기에 불과하기 때문에 쓸데없이 호들갑떨지 말라는 얘기도 하지만, 두 통화의 위상이 증가한 것을 공표하고, 약해지고 있는 달러의 위상을 반영하는 중요한 사건이라고 보기도 한다.
한국은행조차 외환보유고에 금을 포함시킨 것은 외환보유고를 다변화하려는 시도가 금융위기를 지나면서 많은 나라에서 발생하고 있다는 증거이다. 금 외에 캐나다, 오스트레일리아 달러가 많은 국가들에 의해 축적되고 있었고, IMF가 공식화한 것이다.
아직 여기에 엔화 이외의 아시아 통화에 대한 끼일 자리는 없다. G2로 불리는 위안화도 아직 국제화된 기축통화로서의 역할을 하지 못하고 있고, 당분간은 가능성이 전혀 없다. 그러나 달러, 유로의 약세가 진행되면 그 시점이 당겨질 가능성은 있을 것이다.
피드 구독하기:
글 (Atom)