https://en.wikipedia.org/wiki/Andrew_Ng
http://dataconomy.com/10-machine-learning-experts-you-need-to-know/
https://www.quora.com/topic/Andrew-Ng-14
https://www.quora.com/profile/Andrew-Ng/session/39/
https://www.quora.com/When-will-self-driving-cars-be-available-to-consumers/answer/Andrew-Ng
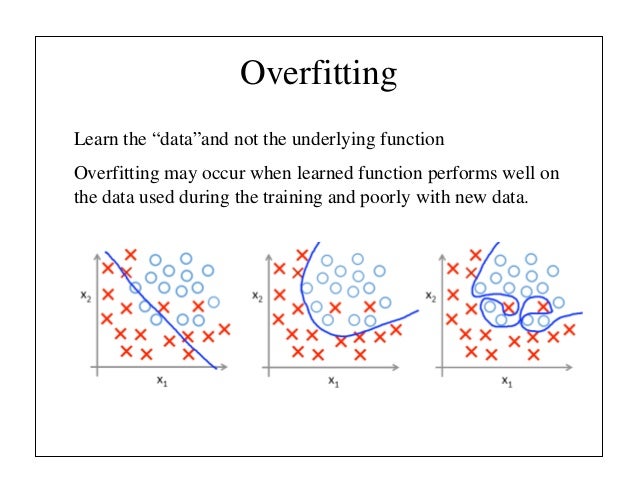
Autonomous driving's biggest problem is addressing all the corner cases--all the strange things that happen once per 10,000 or 100,000 miles of driving. Machine learning is good at getting your performance from 90% accuracy to maybe 99.9%, but it's never been good at getting us from 99.9% to 99.9999%.
http://www.techtimes.com/articles/139832/20160309/baidus-chief-scientist-thinks-autonomous-cars-ready-before-2020.htm
"They will be much safer than human-driven cars," Ng said.
That being said, Baidu is working on an autonomous car, so maybe Ng knows something we don't regarding the technology's advancement.
http://phys.org/news/2016-03-andrew-ng-chief-scientist-chinese.html
One of the things Baidu did well early on was to create an internal platform that made it possible for any engineer to apply deep learning to whatever application they wanted to, including applications that AI researchers like me would never have thought of.
The two things I'm most excited about right now are self-driving cars and speech.
http://www.wsj.com/articles/baidu-to-test-drive-autonomous-cars-in-the-u-s-1458160570
Today, fully autonomous vehicles like Google’s RX450h can handle a wide range of situations, but they still can’t understand a police officer yelling through a bullhorn or process nonverbal cues from other drivers. While these so-called corner cases might seem rare, they in fact occur regularly.
http://fortune.com/2016/03/17/baidu-test-self-driving-cars/
The expanding Sunnyvale, California office is currently 160 employees strong and is led by artificial intelligence scientist Andrew Ng.
http://www.forbes.com/sites/georgeanders/2014/05/19/baidus-coup-ng-aims-to-build-silicon-valleys-new-brain-trust/#7692737c1845
http://venturebeat.com/2014/07/30/andrew-ng-baidu/
In a sense, then, Ng joined a company that had already built momentum in deep learning. He wasn’t starting from scratch.
Ng’s focus now might best be summed up by one word: accuracy.
“Here’s the thing. Sometimes changes in accuracy of a system will cause changes in the way you interact with the device,” Ng said.
But Ng’s strong points differ from those of his contemporaries. Whereas Bengio made strides in training neural networks, LeCun developed convolutional neural networks, and Hinton popularized restricted Boltzmann machines, Ng takes the best, implements it, and makes improvements.
https://www.technologyreview.com/s/544651/baidus-deep-learning-system-rivals-people-at-speech-recognition/
http://www.marketwired.com/press-release/deep-speech-from-baidus-silicon-valley-ai-lab-recognizes-both-english-mandarin-with-nasdaq-bidu-2080829.htm
https://www.technologyreview.com/s/545486/chinas-baidu-releases-its-ai-code/